今天来研读 RAG 的开山之作:《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》
原文链接:https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html
开源代码仓库:https://github.com/huggingface/transformers/blob/master/examples/rag/
交互式Demo:https://huggingface.co/rag/
1. 为什么要引出 RAG?以前的技术有什么不足?
以前预训练神经网络语言模型(如T5、BART、GPT-2)将知识内化于参数之中,这导致了三个主要问题:
知识无法轻松扩展或修改:如果世界知识更新了,参数化模型需要重新训练或者微调。
无法直接提供预测的依据:模型给出了一个答案,人们无法知道它是根据哪条训练数据学到的知识。可解释性和溯源能力不好。
可能产生幻觉(hallucinations):当模型遇到它不会的知识时,不会说“我不知道”,而是基于概率分布开始编造似是而非的“事实”。
鉴于此,混合模型出现了。混合模型将参数化记忆和非参数化记忆(比如基于检索的记忆)结合起来,这解决了上述问题中的一部分,比如知识扩展或修改起来更简单,获得的知识更易于审查和解释。比较经典的代表是 REALM 和 ORQA,这两位采用了 掩码语言模型 + 可微检索器 的配合,取得了不错的成绩。
但依然存在的问题是:上述混合模型做的都是“开放域抽取式问答”。“开放域”指的是,模型在回答问题时,需要在一个巨大的、非结构化的外部数据库中找答案;“抽取式问答”指的是,模型在检索到相关文档段落后,其底座做的事情只是:预测答案在文档中的“起始位置”和“结束位置”,然后把这段原文“抠”出来作为答案。不难发现,“抽取式问答”本质上做的是一种分类任务,预测答案文本的开始和结束概率。
作者认为抽取式问答的做法太过受限,他们想要把检索能力真正赋予“生成任务”,用检索到的信息增强序列到序列(Seq2Seq)模型的生成能力。这就是“检索增强生成(RAG)”。
2. RAG 的基本结构是什么?
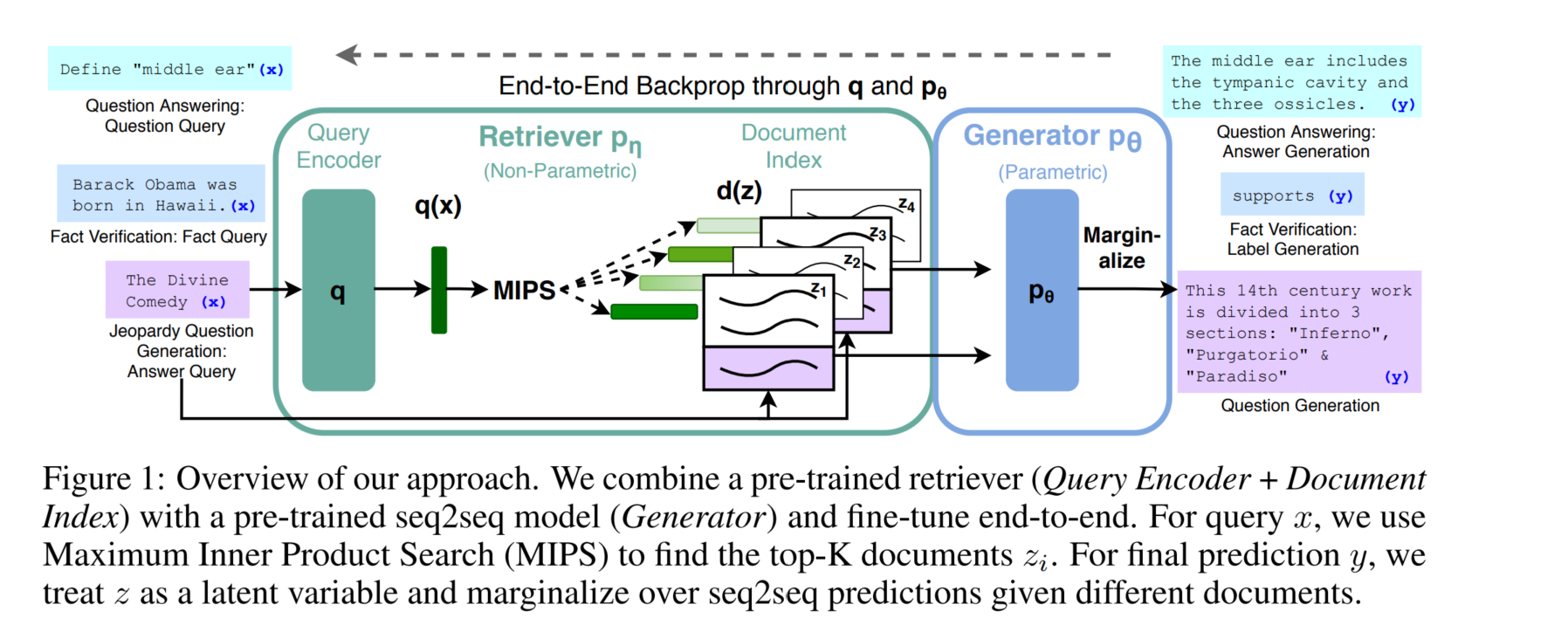
参数化记忆:预训练 seq2seq Transformer (本文是 BART)
非参数化记忆:维基百科的一个稠密向量索引 + 预训练的神经检索器 (本文的神经检索器用的是 DPR,即 Dense Passage Retriever)
训练范式:将上述组件组合在一个概率模型中,并进行端到端的训练。具体而言,DPR 接收输入(input),给出隐变量文档(latent documents),BART接收输入+隐变量文档,给出最终输出(output)。这里将文档的稠密向量视做了一个隐变量,这方便了后续的建模与训练
用数学语言来简要描述这个概率模型,就是:
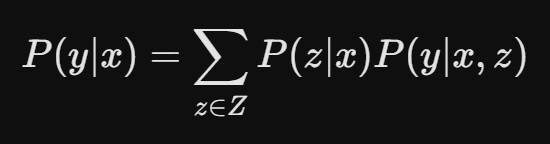
其中 x 指的是 input,Z 指的是整个知识库,z 指的是一篇隐向量文档,y 指的是 output
这里需要注意两点:
[1] 由于 Z 非常庞大,遍历整个知识库的开销会异常大。事实上许多与输入 x 无关的文档,本身被选中的概率 P(z|x) 就很接近 0 ,因此不如将它们视作就是 0 。这就是第一个优化点:top-K 近似。DPR 检索器先快速筛选出最相关的 K 篇文档,我们只对这 K 篇文档运用上述公式计算 P(y|x) 。
[2] 作者提供了两种 P(y|x) 的计算方式。
第一种叫 per-output ,模型认为 K 篇文章中的某一篇单独的文章应当对整句输出 y 负责。在这种方式下,BART 盯着文档 1,把整个句子写完,算出一个条件概率;再盯着文档 2,把整个句子写完……最后,把这 K 篇文章各自生成该句子的概率,乘以它们被检索到的概率,全部加起来(对整句进行边际化)。
第二种叫 per-token,模型认为,写一个长句子时,每一个 token 都可能出自不同的文章。在这种方式下,在生成第 i 个字时,BART 同时看 K 篇文章,计算出 next token 的 K 个概率分布,然后把这些分布混合(加权平均)起来,决定最终吐出哪个字。
由于整套数学框架是非常平滑的,因此这个模型可以在任何 seq2seq 任务上微调,在梯度信息的指导下对生成器和检索器做联合优化。
3.方法与建模是怎样的?
在 Figure 1 的结构图中,有两个主要的组件:检索器 + 生成器。下面给出更精确的数学描述:
检索器:
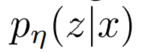
生成器:
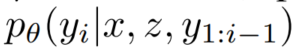
其中,检索器的参数为 η ,它返回在给定查询 x 下的 top-K 文章的概率分布。生成器的参数是 θ ,它返回在给定查询 x ,检索到的文章 z 以及前 i - 1 个输出的 token 下,当前待生成的 token (第 i 个 token)的概率分布。(将历史的输出作为当前的输入是自回归模型的典型表现)
3.1 RAG 模型的建模
按照第 2 节所述,作者提供了 per-output 和 per-token 两种 P(y|x) 的计算方式,这对应了下面两个建模方式:
RAG-Sequence Model:
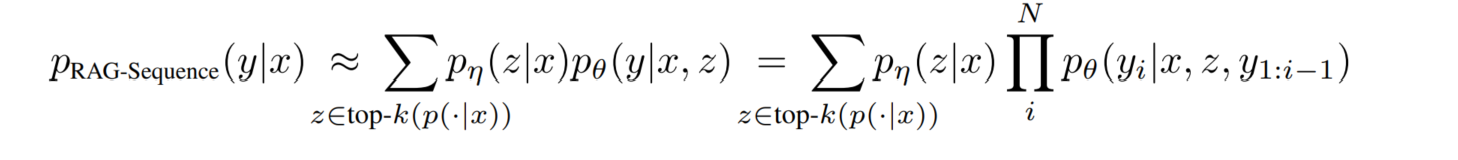
可以看到,在这种计算方式下,是先根据给定的 x 和 z ,计算将一整个目标句子生成完毕的概率,再按照从 x 检索到 z 的条件概率做“加权平均”,不难发现,这正是 per-output 的思想。
RAG-Token Model:
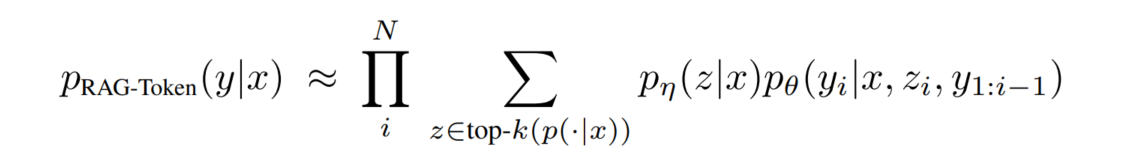
在这种计算方式下,当模型每次要输出第 i 个 token 时,会计算在给定查询 x 与每一篇文档 z 的前提下,生成当前第 i 个 token 的概率,并按照从 x 检索到 z 的条件概率做“加权平均”。最后对 i 累乘,得到最终结果。不难发现,这正是 per-token 的思想。
上述两种计算方式是“约等于”的原因是做了 top-K 近似。
3.2 DPR 检索器的建模
DPR 基于双编码器的架构,可以建模为如下方式:
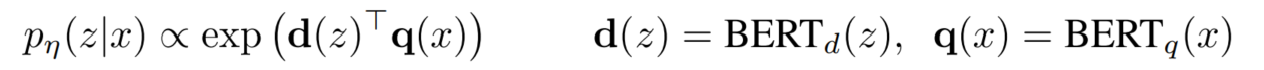
q(x) 是一个专门的查询编码器(Query Encoder)。它把用户的查询 x 通过一个 BERTBASE 模型转化成一个固定的高维稠密向量
d(z) 是一个专门的文档编码器(Document Encoder)。它把外部知识库(维基百科)中的某段文本 z 通过另一个 BERTBASE 模型也转化成一个同等维度的稠密向量。
d(z)Tq(x) 是这两个向量的内积,可以衡量它们的相似度。取指数运算 exp() 是为了将内积的结果映射为正数,以便后面做 Softmax 变成概率。
此外,计算 top-K pη(·|x)属于最大内积搜索(MIPS)问题,是可以在亚线性时间复杂度内被近似解决的(比如采用 FAISS 这种近邻算法)。
3.3 BART 生成器的建模
理论上任何编码器-解码器(Encoder-Decoder)架构都可以作为生成器,这里作者选用了 BART-large ,这个模型在当时(2020年)是比较主流强劲的。选取 Encoder-Decoder 架构,是因为它天然适合处理“输入一段背景文本,输出一段新文本”的任务(例如翻译、摘要、QA)。它的 Encoder 用来通读提示词和文档,Decoder 用来逐字生成。
此外,作者采用将文档 z 和查询 x 直接拼接的方式来输入 BART 生成器,这有利于 BART 的 self-attention 机制在编码阶段,就能让问题中的每一个字与文档中的每一个字进行充分的交叉计算。
3.4 训练方式的建模
考虑每一个input-output样本对
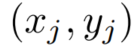
损失函数设计是经典的负对数似然函数:
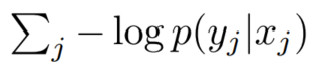
并利用 Adam 优化器做随机梯度下降。
在具体实现上,由于微调文档编码器 BERTd 需要将整个维基百科的文档切片重新用新的 BERTd 编码一遍,并重新建立向量索引,产生极大的算力开销。而作者发现,即使完全冻结 BERTd 的参数,最终 RAG 模型的表现也十分强劲。因此,最终只微调查询编码器 BERTq 和生成器 BART 。
3.5 解码方式的建模
整个 RAG 模型是一个概率模型,概率信息在训练阶段能够指导模型更新参数,那么推理阶段如何使用这些概率信息呢?事实上,RAG 的推理阶段需要解码(Decoding)以找到最优的输出序列,这可以用概率信息来指导。在本模型中,可以用下面的数学语言来描述:
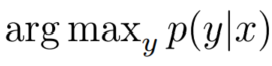
简单来讲,就是在给定的输入(查询)x 下,找到最优的输出序列 y 使得 p(y|x)最大。不过具体实现时,一般采用近似的方法来寻找“最优”。
然而,RAG 模型的两种建模方式具有不同的解码方式。具体而言:
对于 RAG-Token 模型,回顾它的数学描述:
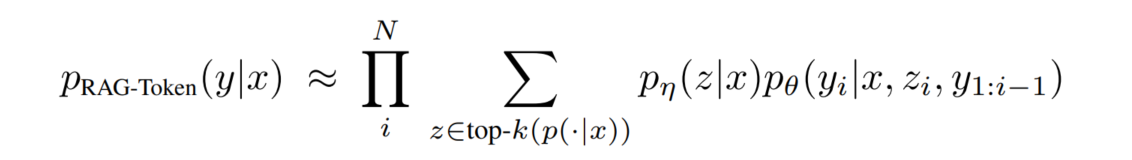
连乘号是在最外层的。这意味着,我们完全可以把里面的求和式当成一个自回归模型的转移概率,即:
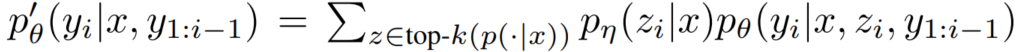
在这种视角下,RAG-Token 模型与其它 seq2seq 的自回归模型是一般无二的。把这个转移概率扔进标准的束搜索解码器(Beam decoder)就能得到很不错的近似最优解。(束搜索是一种搜索最优序列的生成策略的算法,它比“只找到转移概率最大的 token 并输出”的贪婪搜索算法更加“远视”一些,最后能得到top-B个联合概率最大的序列,可以从这B个中选取top-1作为输出)
对于 RAG-Sequence Model,回顾它的数学描述:
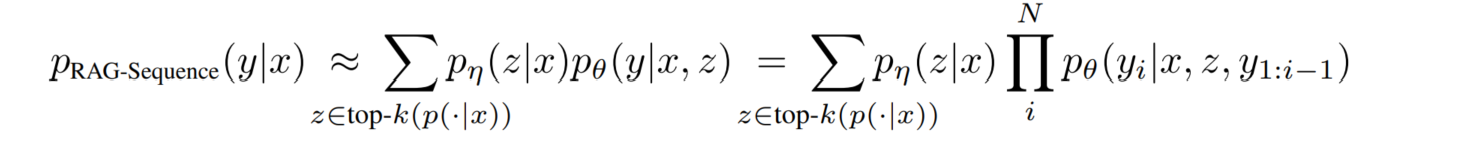
连乘号是在内层的。这意味着,我们无法将它拆解成传统的单字转移条件概率。因此无法用束搜索的算法来解决这个问题。作者引入了两种方案来解决这个问题。
方案一:Thorough Decoding
1.给定输入 x ,分别对文档 z1, z2, ..., zk 运行束搜索,分别得到了 B 个候选序列,组成一个候选集 Y 。
2.由于束搜索在执行算法过程中,会将概率“得分”不太高的分支剪去,因此可能出现文档 z1 得到的 Beam 里某些高分的序列,在其它文档的束搜索过程中被剪枝丢弃,于是在 Beam 中没有出现。因此,为了保证总边际概率计算的正确性,必须将这些缺失概率得分的序列重新过一遍模型前向传播,计算概率“得分”。
3.补齐所有文档对候选集 Y 中每个句子的打分后,乘以各自的文档检索概率并求和,挑出得分最高的句子。
随着输出序列长度的增大,补齐前向传播的开销会越来越大,这时可以考虑下面的方案。
方案二:Fast Decoding
在这个方案下,如果发现目标序列 y 在给定的问询 x 和文档 zi 下没有在对应的 Beam 出现,直接认为对应的概率打分 Pθ(y|x, zi) = 0
虽然丧失了一点数学严谨性,但是在工程上极大地减小了开销。
4.有怎样的结论?
(具体实验过程和数据分析可以参考原文)
RAG 模型在开放域问答任务上取得了当时 SOTA(state of the art) 的成绩,相比起纯参数化的 BART 更加事实、具体,并在上述设计的一套端到端的轻量训练方案下完全成立且十分高效。此外,作者还验证了 RAG 模型的热插拔(Hot-swapped)能力,即在不关闭模型系统、不重新训练任何参数的情况下,将旧的非参数化知识库拔掉,插上一个新的非参数化知识库,以此更新 RAG 模型。当然,热插拔能力的实现,很大程度上是由文档编码器 BERTd 的参数冻结 + 预训练模型的 zero-shot 泛化能力来保证的。